随机数
坏例子:不要使用rand()
注:截图来自rand() Considered Harmful,youtube上也有,演讲者为Stephan T. Lavavej。

Stephan 列出了如下缺陷:
- 不应该使用NULL,而应该使用nullptr
- time()调用时钟周期为1Hz,速度慢
- time()返回值为time_t,隐式转换到srand所需的unsigned int导致编译器产生C4244警告
- srand()接收一个32-bit的种子,精度低
- rand()返回值范围过小[0, 32767]
- 对rand()取余导致结果很大概率上不是均匀分布
- rand()采用线性同余算法,质量低
即使假设rand()结果均匀分布,使用取余(%)仍然有问题:

明显可以得知,当取余对象不能被rand()范围整除时,有一部分数值产生的余数概率略低。上图的例子中,整百数到整百数+99共100个数字可以均匀得到[0,99]之间的结果,但[32700,32767]内只能产生[0,67]之间的结果。
Accelerated C++ 7.4.4节对此有更详尽的描述:
当商(quotient)被当做n且为小整数时,许多伪(pseudo)随机数生成器制造出来的余数(remainder)并不很随机。例如rand()的连续执行结果非偶即奇(这并不十分罕见),这种情况下如果n是2,连续执行rand()%n获得的不是0就是1。
另一方面,如果n是大数,且被生成之最大值并非均匀地(evenly)可被n除尽,那么某些余数(remainder)的出现概率会远高于其他。假设最大数是36767而n是2000, 17个生成值(500, 2500, …, 30500, 32500)将映射至500,而16个生成值(1500, 3500, …, 31500)将映射至1500。这个情况在n越大时越糟糕。
进一步,使用浮点数能消除结果不均匀的问题吗?
来看Stack Overflow 上Justin Niessner的答案(这位仁兄被批判的够惨。。。)使用浮点数产生随机数的例子:

上图可以看出,只有rand()返回32767时结果为99,概率低于其他数值,仍然是非均匀的。
再来看一个使用浮点数的改进版例子:

结果比上一个例子均匀了很多,但仍然不是完全均匀的。Stephan给的解释非常妙: 你永远无法将32767只鸽子均匀地放进100个笼子里!
继续谈浮点数。

当输入样本足够大时(2^64),double的精度(有效位数53bits)无法表示了。 因此,别用浮点数搞事!2333333
真是realy realy bad。。。
正确的打开方式
C++11版标准库中数值组件(numeric component)中随机数及其分布(random number and distribution)就是干这个事的。
《C++标准库》第二版谈到:
自C++11起,C++标准库包含一个随机数程序库(random-number library),提供众多class和type用来满足新手和专家对于随机数及其分布(distribution)的需求。
C++标准库提供多个引擎,那是随机性的源头。这些引擎会产生随机的无正负号(random unsigned value),它们被均匀分布(uniformly distributed)于一个预定义的最小值和最大值之间;而所谓distribution会把那些值转换为随机数(random number),后者将根据使用者提供的参数被线性或非线性地分布。
一个基本的例子(假设已经包含了所需头文件):
#include <random>
// create default engine as source of randomness
std::default_random_engine dre;
// use engine to generate integral numbers between 10 and 20 (both included)
std::uniform_int_distribution<int> di(10, 20);
for (int i = 0; i < 20; i++) {
std::cout << di(dre) << " ";
}
std::cout << std::endl;
// use engine to generate floating-point numbers between 10.0 and 20.0 (10.0 included, 20.0 not included)
std::uniform_real_distribution<double> dr(10, 20);
for (int i = 0; i < 8; i++) {
std::cout << dr(dre) << " ";
}
std::cout << std::endl;
产生随机数的办法是,将引擎dre分别于两个分布di和dr组合起来:
- 引擎作为随机性的源头,它们是function object,能够产生随机的无正负值,并均匀分布于一个预定义的最小和最大值之间。
- 分布表示以何种手法将这些随机值(random value)转换为随机数(random number),后者分布于一个由使用者给定的参数所决定的区间内。
引擎、分布有很多,常用的不多,Stephan给出了他推荐的3个引擎:
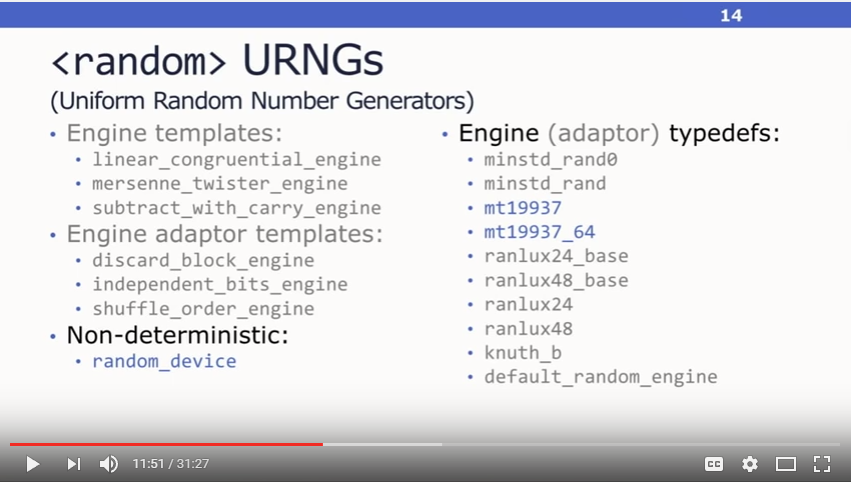
相比之下,仍然是mt19937和mt19937_64更常用。
一些值得注意的地方

- 引擎生成随机数很快,但构造不够快,应该尽量避免多次构造引擎
- 同一个引擎的初始状态是相同的,会产生相同的随机数序列
- 生成随机数的调用不是const的,不是线程安全的,应该注意避免多线程共用引擎。
- 不要只使用引擎却不指定分布(若区间不吻合就需要加上modulo operator%,导致前文所述的取余问题)
- 慎用default_random_engine,不同平台所使用的算法有可能不同
- 避免使用random_shuffle,它调用了rand()函数,囧
- 慎用shuffle函数,它接受一个引擎却不能指定区间,且传入方式为右值(&&),导致无法重用引擎,可能导致多次构造引擎